The nature of Microsoft’s directory service clients provides for inherent fault-tolerance in the event of a failure. There are often questions about how, or if, this failover works properly. In this post, we are going to see the failover in action. Before we get started though, there are some conditions that can prevent this standard behavior which are worth discussing. This is not a comprehensive list but these are a few common reasons that a client may not failover:
- There are no other Global Catalog servers available
- Client is unable to perform host or short name resolution to locate another DC
- IPSec or firewall rules restrict connectivity to original DC
There are lots of different failover scenarios but in this post we focus on authentication failover. In the step-by-step review of the trace, we are going to see the following functional steps (these steps are not a direct map to the trace review below):
- An XP workstation, XP01 (10.10.17.145), is connected to one domain controller, 2K3DC02 (10.10.17.250)
- The workstation is locked with the Interactive logon: Require Domain Controller authentication to unlock workstation policy set
- 2K3DC02 (10.10.17.250) is taken offline
- A second domain controller, 2K3DC01 (10.10.17.10) is brought back online
- XP01 will be unlocked by failing over from 2K3DC02 to 2K3DC01
At the end of this post there are links to network captures for other types of failover as well.
In the environment there are two 2003 R2 domain controllers and one Windows XP workstation. Both domain controllers are running DNS and are acting as global catalog servers. The XP workstation is configured with 10.10.17.10 as its primary DNS server and 10.10.17.250 as its secondary DNS server.
1. 2K3DC01 is taken offline. XP01 is booted and connects to 2K3DC02. Frames 10 and 11 show successful Kerberos communication between XP01 and 2K3DC02.
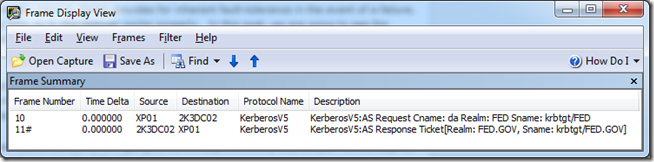
2. XP01 is locked. 2K3DC02 is taken offline. 2K3DC01 is brought online. An attempt is made to unlock XP01 which requires communication with a domain controller. Frame 15 is sent because 5 seconds after XP01 sent the first AS_REQ in frame 14, no response has been received from 2K3DC02.
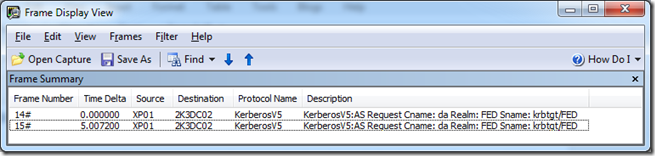
3. With no reply from 2K3DC02 to XP01, a DNS query is made by XP01 in frame 16 to find domain controllers running the Kerberos service. In frame 17, 2K3DC01 returns four domain controllers which have registered the Kerberos service record.

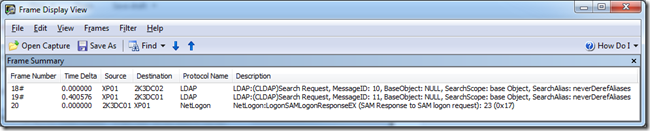
4. XP01 attempts connection to both 2K3DC02 (frame 18) and 2K3DC02 (frame 19). Only 2K3DC01 will respond (frame 20).
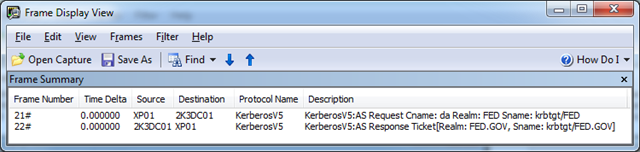
5. The Kerberos AS_REQ which initially failed between XP01 and 2K3DC02 is now reissued in frame 21 from XP01 to 2K3DC01. 2K3DC01 will answer this AS_REQ with an AS_REP in frame 22.
No special changes had to be made or commands run to allow for the graceful failover of the XP client in finding an alternate domain controller to unlock the workstation. This fault-tolerance is native to directory service clients and a major advantage of service records over server records.
The full trace was taken in Netmon 3.2 and is not much larger than these packets outline in this blog but I have included the trace below (dcFailover.cap) so that you can view any details that you would like.
As we said early on, there are lots of types of failover and lots of services to failover some of which may not be as graceful as Kerberos. The following network captures illustrate failover behavior which occurs during a variety of functions. Though the functions are unique, you may see overlap in the services that are failing over in the captures.
In the middle of a bulk add of users, I shut off the network on one DC and brought the network online for another. Without stopping and restarting the script, my client gracefully failed over to another domain controller. I did not use ADUC for this test because ADUC is stateful on object creation. Also, I could not use NET USER because of its legacy behavior which I will be discussing in a future post. So, I used a FOR loop and DSADD to create the users.
On my XP client, I had a DFS session open for domainSYSVOL. I then browsed to the SYSVOL subdirectory of this volume. From there, I shut off the network on the one DC I was connected to and brought the network online for the other domain controller. I then attempted to browse further into the directory structure to the Policies folder. In the trace, you can see the failover from my originally connected DC to the newly onlined DC.
Early on in the first logon attempt of this user to this machine, I remove the domain controller that the user began authentication with and replace it with another. The client is able to gracefully finish logging on to the workstation with the replaced domain controller.
After launching GPUPDATE /FORCE on a workstation and allowing it to connect to one DC, I shut that DC off and watch it failover to another DC to finish applying policy.
If you’d like to see how any other service responds to outages, please let us know.